I don't know that it's possible to say that any single part of the data mining process is the "most important", but there are three junctures which are absolutely critical to successful data mining: 1. problem definition, 2. data acquisition and 3. model validation. Failures at other points will more often lead to loss in the form of missed opportunities.
Problem Definition
Problem definition means understanding the "real-world" or "business" problem, as opposed to the technical modeling or segmentation problem. In some cases, deliberation on the nature of the business problem may reveal that an empirical model or other sophisticated analysis is not needed at all. In most cases, the model will only be one part of a larger solution. This is a point worth elaboration. Saying that the model is only part of a larger solution is not merely a nod to the database which feeds to model and the reporting system which summarizes model performance in the field. The point here is that a predictive model or clustering mechanism must somehow be fit into the architecture of the solution some how. The important question here is: "How?" Models sometimes solve the whole (technical) problem, but in other situations, optimizers are run over models, or models are used to guide a separate search process. Deciding exactly how the model will be used with the total solution is not always trivial.
Also: attacking the wrong business problem all but ensures failure, since the chances of being able to quickly and inexpensively "re-engineer" a fully-constructed technical solution for the real business problem are slim.
Data Acquisition
Data acquisition refers to the actual collection of whatever data is to be used to build the model. If, for instance, sampling is not representative of the statistical universe to which to model will be applied, all bets are off. More than once, I have received analytical extracts of databases from other individuals which, for instance, contained no accounts with last names starting with the letter 'P' through 'Z'! Clearly, a very arbitrary sample had been drawn. The same thing happens all the time when database programmers naively query for limited ranges of account numbers or other record index values ("all account numbers less than 140000").
With larger and larger data sets being examined by data miners, the need for sampling will not go away in the foreseeable future. Sampling has long been studied within statistics and there are far too many pitfalls in this area to ignore the issue. My strong recommendation is to learn about it, and I suggest a book like Sampling: Design and Analysis Sampling: Design and Analysis by Sharon L. Lohr (ISBN-13: 978-0534353612).
Model Validation
Model validation gets my vote for "most important step in any data mining project". This is where- to the extent it's possible- the data miner determines how much the model really has learned. As I write this, it is the end of the year 2007, yet, amazingly people who call themselves "analysts" continue to produce models without delivering any sort of serious evidence that their models work. Years after the publication of "Magical Thinking in Data Mining: Lessons From CoIL Challenge 2000" by Charles Elkan, in which the dangers of testing on the training set were (yet again!) demonstrated, models are not receiving the rigorous testing they need.
"Knowing what you know" (and what you don't know) is critical. No model is perfect, and understanding the limits of likely performance is crucial. This requires the use of error resampling methods, such as holdout testing, k-fold cross-validation and bootstrapping. Performance of models, once deployed, should not be a surprise, nor a matter of faith.
Friday, December 14, 2007
Thursday, November 08, 2007
Random things...
I was just looking at my favorite economics blog, The Skeptical Optimist, and saw a post on randomness based on two books the blog author, Steve Conover is reading called The Black Swan and Fooled by Randomness. This caught my eye--a quote from one of the two books (it was unclear to me which one):
He then gives an example of two stock pickers, one of whom gets it "right" about 1/2 the time, and a second who gets it right 12 consecutive times. The punch line is this:
I personally don't agree philosophically with the role of randomness (I would prefer to say that many outcomes are unexplained then say randomness is the "reason" or "cause"--randomness does nothing itself, it is our way of saying "I don't know why" or "it is too hard to figure out why").
But that said, this is an extremley important principal for data miners. We have all seen predictive models that apparently do well on one data set, and then does poorly on another. Usually this is attributed to overfit, but it doesn't have to be solely an overfit problem. David Jensen of UMass described in one paper the phenomenon of oversearching for models in the paper Multiple Compisons in Induction Algorithms, where you could happen upon a model that works well, but is just a happenstance find.
The solution? One great help in overcoming these problems is through sampling--the train/test/validate subset method, or by resampling methods (like bootstrapping). But having the mindset of skepticism about models helps tremendously in digging to ensure the models truly are predictive and not just a random matching of the patterns of interest.
Here's an example of his point about randomness: How many times have you heard about mutual fund X's "superlative performance over the last five years"? Our typical reaction to that message is that mutual fund X must have better managers than other funds. Reason: Our minds are built to assign cause-and-effect whenever possible, in spite of the strong possibility that random chance played a big role in the outcome.
He then gives an example of two stock pickers, one of whom gets it "right" about 1/2 the time, and a second who gets it right 12 consecutive times. The punch line is this:
Taleb's point: Randomness plays a much larger role in social outcomes than we are willing to admit—to ourselves, or in our textbooks. Our minds, uncomfortable with randomness, are programmed to employ hindsight bias to provide retroactive explanations for just about everything. Nonetheless, randomness is frequently the only "reason" for many events.
I personally don't agree philosophically with the role of randomness (I would prefer to say that many outcomes are unexplained then say randomness is the "reason" or "cause"--randomness does nothing itself, it is our way of saying "I don't know why" or "it is too hard to figure out why").
But that said, this is an extremley important principal for data miners. We have all seen predictive models that apparently do well on one data set, and then does poorly on another. Usually this is attributed to overfit, but it doesn't have to be solely an overfit problem. David Jensen of UMass described in one paper the phenomenon of oversearching for models in the paper Multiple Compisons in Induction Algorithms, where you could happen upon a model that works well, but is just a happenstance find.
The solution? One great help in overcoming these problems is through sampling--the train/test/validate subset method, or by resampling methods (like bootstrapping). But having the mindset of skepticism about models helps tremendously in digging to ensure the models truly are predictive and not just a random matching of the patterns of interest.
Tuesday, October 23, 2007
Follow-Up to: Statistics: Why Do So Many Hate It?
In a question posted Oct-14-2007 to Yahoo! Answers, user lifetimestudentofmath asked:
How would you run this regression?
A relationship between beer expenditure and income was tested. The relationship may be qualitatively effected by gender. How would you test the hypothesis that women spend less money on beer than women?
My guess is that this is a homework question, and that the teacher wants students to use a dummy variable to represent gender, so that a simple interpretation of gender's coefficient will reveal the answer.
In reality, of course, the interaction of income and gender may yield a more nuanced answer. What if two regressions were performed, one for men and the other for women, with income as the predictor and beer expenditure as the target, and the regression lines crossed? Such a result precludes so simple a response as "men spend more on beer".
This question suggests another reason so many people hate statistics: its subtlety. The annoying thing about reality (which is the subject of statistical study), is that it is so complicated. Even things which seem simple will often reveal surprisingly complex behavior. The problem is that people don't want complicated answers. Although my response is: It is foolish to expect simple solutions to complicated problems, the fundamental, irreducible complexity of reality- which is mirrored in statistics- also drives negative feelings toward statistics.
How would you run this regression?
A relationship between beer expenditure and income was tested. The relationship may be qualitatively effected by gender. How would you test the hypothesis that women spend less money on beer than women?
My guess is that this is a homework question, and that the teacher wants students to use a dummy variable to represent gender, so that a simple interpretation of gender's coefficient will reveal the answer.
In reality, of course, the interaction of income and gender may yield a more nuanced answer. What if two regressions were performed, one for men and the other for women, with income as the predictor and beer expenditure as the target, and the regression lines crossed? Such a result precludes so simple a response as "men spend more on beer".
This question suggests another reason so many people hate statistics: its subtlety. The annoying thing about reality (which is the subject of statistical study), is that it is so complicated. Even things which seem simple will often reveal surprisingly complex behavior. The problem is that people don't want complicated answers. Although my response is: It is foolish to expect simple solutions to complicated problems, the fundamental, irreducible complexity of reality- which is mirrored in statistics- also drives negative feelings toward statistics.
Wednesday, October 17, 2007
Statistics: Why Do So Many Hate It?
In Why is Statistics So Scary?, the Sep-26-2007 posting to the Math Stats And Data Mining Web log, the author wonders why so many people exhibit negative reactions to statistics.
I've had occasion to wondered about the same thing. I make my living largely from statistics, and have frequently received unfavorable reactions when I explain my work to others. Invariably, such respondents admit the great usefulness of statistics, so that is not the source of this negativity. I am certain that individual natural aptitude for this sort of work varies, but I do not believe that this accounts for the majority of negative feelings towards statistics.
Having received formal education in what I call "traditional" or "classical" statistics, and having since assisted others studying statistics in the same context, I suggest that one major impediment for many people is the total reliance by classical statisticians on a large set of very narrowly focused techniques. While they serve admirably in many situations, it is worth noting the disadvantages of classical statistical techniques:
1. Being so highly specialized, there are many of these techniques to remember.
2. It is also necessary to remember the appropriate applications of these techniques.
3. Broadly, classical statistics involves many assumptions. Violation of said assumptions may invalidate the results of these techniques.
Classical techniques were developed largely during a time without the benefit of rapid, inexpensive computation, which is very different from the environment we enjoy today.
The above were major motivations for me to embrace newer analytical methods (data mining, bootstrapping, etc.) in my professional life. Admittedly, newer methods have disadvantages of their own (not the least of which is their hunger for data), but it's been my experience that newer methods tend to be easier to understand, more broadly applicable and, consequently, simpler to apply.
I think the broader educational question is: Would students be better served by one or more years of torture, imperfectly or incorrectly learning myriad methods which will soon be forgotten, or the provision of a few widely useful tools and an elemental-level of understanding?
I've had occasion to wondered about the same thing. I make my living largely from statistics, and have frequently received unfavorable reactions when I explain my work to others. Invariably, such respondents admit the great usefulness of statistics, so that is not the source of this negativity. I am certain that individual natural aptitude for this sort of work varies, but I do not believe that this accounts for the majority of negative feelings towards statistics.
Having received formal education in what I call "traditional" or "classical" statistics, and having since assisted others studying statistics in the same context, I suggest that one major impediment for many people is the total reliance by classical statisticians on a large set of very narrowly focused techniques. While they serve admirably in many situations, it is worth noting the disadvantages of classical statistical techniques:
1. Being so highly specialized, there are many of these techniques to remember.
2. It is also necessary to remember the appropriate applications of these techniques.
3. Broadly, classical statistics involves many assumptions. Violation of said assumptions may invalidate the results of these techniques.
Classical techniques were developed largely during a time without the benefit of rapid, inexpensive computation, which is very different from the environment we enjoy today.
The above were major motivations for me to embrace newer analytical methods (data mining, bootstrapping, etc.) in my professional life. Admittedly, newer methods have disadvantages of their own (not the least of which is their hunger for data), but it's been my experience that newer methods tend to be easier to understand, more broadly applicable and, consequently, simpler to apply.
I think the broader educational question is: Would students be better served by one or more years of torture, imperfectly or incorrectly learning myriad methods which will soon be forgotten, or the provision of a few widely useful tools and an elemental-level of understanding?
Tuesday, October 16, 2007
See The World
I recently had the pleasure of attending the Insightful Impact 2007 conference, where I especially enjoyed a presentation on ensemble methods by two young, up-and-coming, aspiring data miners: Brian Siegel and his side-kick... Deke Abbott, or Dean Abner, or some such.
I am frequently asked what is the best way to learn about data mining (or machine learning, statistics, etc.). I get a great deal of information from reading, either books or white papers and reports which are available for free, on-line. Another great learning experience involves attendance of conferences and trade shows. I don't travel a great deal and find it convenient to attend whatever free or cheap events happen to be within close distance. I also try to get to KDD when it's on the east coast of the United States. Aside from the presentations, events like these are an opportunity to get away from the muggles and spend some time with other data miners. I highly recommend it.
Nice job, Dean and Brian.
I am frequently asked what is the best way to learn about data mining (or machine learning, statistics, etc.). I get a great deal of information from reading, either books or white papers and reports which are available for free, on-line. Another great learning experience involves attendance of conferences and trade shows. I don't travel a great deal and find it convenient to attend whatever free or cheap events happen to be within close distance. I also try to get to KDD when it's on the east coast of the United States. Aside from the presentations, events like these are an opportunity to get away from the muggles and spend some time with other data miners. I highly recommend it.
Nice job, Dean and Brian.
Friday, August 31, 2007
Interesting real-world example of Simpson's Paradox
At MineThatData blog there is a very interesting post on email marketing productivity was very interesting, and a good example of Simpson's Paradox (as I posted in the comments). The key (as always) is that there are disproportionate population sizes with quite disparate results. As Kevin points out in the post, there is a huge difference between the profit due to engaged customers vs. those who aren't engaged, but the number of non-engaged customers dwarfs the engaged.
The problem we all have in analytics is finding these effects--unless you create the right features, you never see it. To create good features, you usually need to have moderate to considerable expertise in the domain area to know what might be interesting. And yes, neural networks can find these effects automatically, but you still have to back out the relationships between the features found by the NNets and the original inputs in order to interpret the results.
Nevertheless, this is a very important post if for no other reason but to alert practitioners that relative sizes of groups of customers (or other natural groupings in the data) matter tremendously.
The problem we all have in analytics is finding these effects--unless you create the right features, you never see it. To create good features, you usually need to have moderate to considerable expertise in the domain area to know what might be interesting. And yes, neural networks can find these effects automatically, but you still have to back out the relationships between the features found by the NNets and the original inputs in order to interpret the results.
Nevertheless, this is a very important post if for no other reason but to alert practitioners that relative sizes of groups of customers (or other natural groupings in the data) matter tremendously.
Tuesday, August 21, 2007
Little League pitch counts -- data vs decisions revisited
I posted recently on the new rules in pitch counts for Little League. I've had to defend my comments recently (in a polite way on this blog, and a bit more strenuously in person with friends who have sons pitching in LL), but was struck again about this issue while watching the LL World Series on ESPN.
On the ESPN web site I read this article on pitch counts, and found this comment on point:
In other words, coaches know that it isn't pitch counts per se that cause the problems, but rather the number of months of the year the kids are pitching.
Interestingly, there is no ban on breaking pitches, though when I talk to coaches, there is speculation that these cause arm problems. In fact, on the Little League web site, they state:
I'm glad they are studying it, but the decision not to act to ban breaking pitches due to a lack of data is interesting since there is also a lack of data with pitch counts, but it didn't stop the officials from making rules there! Hopefully with the new pitch count rules, and the new data collected, we can see of the data bears out this hypothesis.
On the ESPN web site I read this article on pitch counts, and found this comment on point:
What's interesting here is that the 20-pitch specialist is the residue of a change that did not, strictly speaking, emanate from problems within Little League itself. Around the coaching community, it is widely understood that the advent of nearly year-round travel (or "competitive") ball is one of the primary reasons for the rise in young arm problems. In some ways, Little League has made a pitch-count adjustment in reaction to forces that are beyond its control.
Travel ball has become an almost de facto part of a competitive player's baseball life -- just as it has in soccer, basketball and several other youth sports. An alphabet soup of sponsoring organizations, from AAU to USSSA, BPA and well beyond, offers the opportunity to play baseball at levels -- and sheer numbers of games -- that a previous generation of players would have found mind-boggling.
But travel ball is here to stay -- and so too, apparently, is a new approach by Little League to containing the potential damage to young arms. So get used to the 20-pitch kid. He's a closer on the shortest leash imaginable.
In other words, coaches know that it isn't pitch counts per se that cause the problems, but rather the number of months of the year the kids are pitching.
Interestingly, there is no ban on breaking pitches, though when I talk to coaches, there is speculation that these cause arm problems. In fact, on the Little League web site, they state:
While there is no medical evidence to support a ban on breaking pitches, it is widely speculated by medical professionals that it is ill-advised for players under 14 years old to throw breaking pitches,” Mr. Keener said. “Breaking pitches for these ages continues to be strongly discouraged by Little League, and that is an issue we are looking at as well. As with our stance on pitch counts, we will act if and when there is medical evidence to support a change.
I'm glad they are studying it, but the decision not to act to ban breaking pitches due to a lack of data is interesting since there is also a lack of data with pitch counts, but it didn't stop the officials from making rules there! Hopefully with the new pitch count rules, and the new data collected, we can see of the data bears out this hypothesis.
Wednesday, August 15, 2007
KDNuggets Poll on "Data Mining" as a term
KDNuggets has a new poll on whether or not "data mining" should still be used to describe the kind of analysis we all know and love. It is still barely winning, but interesting, Knowledge Discovery is almost beating it out as the better term.
The latest Y2K bug--and why mean values don't tell the whole story
I was interested in the recent hubbub over surface temperatures as first written in NASA's Daily Tech, and picked up by other news sources. (Note: the article doesn't render well for me in Firefox, but IE is fine).
However, I found this article describing the data even more interesting, from the Climate Audit Blog. From a data mining / statistics perspective, it was the distribution of the errors that was interesting. I had read in the media (sorry-don't remember where) that there was an average error of 0.15 deg. C due to the Y2K error in the data--that didn't seem too bad. But, at the blog, he describes that the errors are (1) bimodal, (2) postively skewed (hence the positive average error), and (3) typically much larger than 0.15 deg. So while on average it doesn't seem bad, the surface temperature errors are indeed significant.
Once again, averages can mask data issues. Better to augment averages with other metrics, or better yet, visualize!
However, I found this article describing the data even more interesting, from the Climate Audit Blog. From a data mining / statistics perspective, it was the distribution of the errors that was interesting. I had read in the media (sorry-don't remember where) that there was an average error of 0.15 deg. C due to the Y2K error in the data--that didn't seem too bad. But, at the blog, he describes that the errors are (1) bimodal, (2) postively skewed (hence the positive average error), and (3) typically much larger than 0.15 deg. So while on average it doesn't seem bad, the surface temperature errors are indeed significant.
Once again, averages can mask data issues. Better to augment averages with other metrics, or better yet, visualize!
Saturday, August 11, 2007
Rexer Analytics Data Miner Survey, Aug-2007
Rexer Analytics recently distributed a report summarizing the findings of their survey of data miners (observation count=214, after removal of tool vendor employees).
Not surprisingly, the top two types of analysis were: 1. predictive modeling (89%) and 2. segmentation/clustering (77%). Other methods trail off sharply from there.
The top three types of algorithms used were: 1. decision trees (79%), 2. regression (77%) and 3. cluster analysis (72%). It would be interesting to know more about the specifics (which tree-induction algorithms, for instance), but I'd be especially interested in what forms of "regression" are being used since that term covers a lot of ground.
Responses regarding tool usage were divided into never, occasionally and frequently. The authors of the report sorted tools in decreasing order of popularity (occasionally plus frequently used). Interestingly, your own code took second place with 45%, which makes me wonder what languages are being used. (If you must know, SPSS came in first, with 48%.)
When asked about challenges faced by data miners, the top three answers were: 1. dirty data (76%), 2. unavailability of/difficult access to data (51%) and 3. explaining data mining to others (51%). So much for quitting my job in search of something better!
Not surprisingly, the top two types of analysis were: 1. predictive modeling (89%) and 2. segmentation/clustering (77%). Other methods trail off sharply from there.
The top three types of algorithms used were: 1. decision trees (79%), 2. regression (77%) and 3. cluster analysis (72%). It would be interesting to know more about the specifics (which tree-induction algorithms, for instance), but I'd be especially interested in what forms of "regression" are being used since that term covers a lot of ground.
Responses regarding tool usage were divided into never, occasionally and frequently. The authors of the report sorted tools in decreasing order of popularity (occasionally plus frequently used). Interestingly, your own code took second place with 45%, which makes me wonder what languages are being used. (If you must know, SPSS came in first, with 48%.)
When asked about challenges faced by data miners, the top three answers were: 1. dirty data (76%), 2. unavailability of/difficult access to data (51%) and 3. explaining data mining to others (51%). So much for quitting my job in search of something better!
Saturday, July 28, 2007
NY Times Defines Data Mining
In their article here, the NY Times defines data mining in this way:
While I recognize that the NYT is not a technical body, and reporters often get the gist of technology wrong, this particular kind of definition has swept the media to such a degree that the term "data mining" may never recover.
The definition itself has problems, such as
1) searching databases per se I'm sure is not what they mean by data mining; almost certainly they mean programs that automatically searching the databases to find interesting patterns (and presumably horribly overfitting int he process, registering many false positives) as the problem. After all, a Nexus search searches a database and no one raises an eyebrow at that.
2) the problem with the searching is not the searching (or the data mining in their terminology), but the data that is being searched. Therefore the headline of the story, "Mining of Data Prompted Fight Over Spying" should probably more accurately read something like "Data allowed to be Mined Prompted Fight Over Spying"
It is this second point that I have argued over with others who are concerned about privacy, and therefore have become anti-data-mining. It is the data that is the problem, not the mining (regardless of the definition of mining). But I think the term "data mining" resonates well and generates a clear mental image of what is going on, which is why it gained popularity in the first place.
So I predict that within 5 years, few data miners (and I consider myself one of them) will refer to him/herself as a data miner, nor will we describe what we do as data mining. Predictive Analytics anyone?
It is not known precisely why searching the databases, or data mining, raised such a furious legal debate. But such databases contain records of the phone calls and e-mail messages of millions of Americans, and their examination by the government would raise privacy issues.
While I recognize that the NYT is not a technical body, and reporters often get the gist of technology wrong, this particular kind of definition has swept the media to such a degree that the term "data mining" may never recover.
The definition itself has problems, such as
1) searching databases per se I'm sure is not what they mean by data mining; almost certainly they mean programs that automatically searching the databases to find interesting patterns (and presumably horribly overfitting int he process, registering many false positives) as the problem. After all, a Nexus search searches a database and no one raises an eyebrow at that.
2) the problem with the searching is not the searching (or the data mining in their terminology), but the data that is being searched. Therefore the headline of the story, "Mining of Data Prompted Fight Over Spying" should probably more accurately read something like "Data allowed to be Mined Prompted Fight Over Spying"
It is this second point that I have argued over with others who are concerned about privacy, and therefore have become anti-data-mining. It is the data that is the problem, not the mining (regardless of the definition of mining). But I think the term "data mining" resonates well and generates a clear mental image of what is going on, which is why it gained popularity in the first place.
So I predict that within 5 years, few data miners (and I consider myself one of them) will refer to him/herself as a data miner, nor will we describe what we do as data mining. Predictive Analytics anyone?
Saturday, July 21, 2007
Idempotent Capable Modeling Algorithms
In Idempotent-capable Predictors, the Jul-06-2007 posting to Machine Learning (Theory) Web log, the author suggests the importance of empirical models being idempotent (in this case, meaning that they can use one of the input variables as the model output).
This is of interest since: 1. One would like to believe that the modeling process could generate the right answer, once it had actually been given the right answer, and 2. It is not uncommon for analysts to design inputs to models which give "hints" (which are partial solutions of the problem). In the article mentioned above, it is noted that some typical modeling algorithms, such as logistic regression, are not idempotent capable. The author wonders how important this property is, and I do, too. Thoughts?
This is of interest since: 1. One would like to believe that the modeling process could generate the right answer, once it had actually been given the right answer, and 2. It is not uncommon for analysts to design inputs to models which give "hints" (which are partial solutions of the problem). In the article mentioned above, it is noted that some typical modeling algorithms, such as logistic regression, are not idempotent capable. The author wonders how important this property is, and I do, too. Thoughts?
Tuesday, July 17, 2007
More Statistics Humor
In February of this year, Dean posted a witty comment regarding statistics which ignited an amusing exchange of comments (Quote of the day). Readers who found that item entertaining may also appreciate the quotes listed at the bottom of The Jesus Tomb Math.
Wednesday, July 04, 2007
When Data and Decisions Don't Match--Little League Baseball
Maybe it's because I used to pitch in Little League when I was a kid, but this article in the July 1 Union Tribune really struck me. It describes how injuries to Little League pitchers has increased significantly over the past 10 years from one a week to 3-4 a day with elbow and/or shoulder injuries from baseball. What's the cause? Apparently, as the article indicates, it is from "overuse" (i.e., pitchers pitching too much). And here is the key statistic:
In San Diego, where I'm located, this can be a big problem because there is baseball going on all year round (even in Little League, where there are summer and fall leagues, plus the ever-present year-round traveling teams).
So what's the solution? A year ago or so they instituted an 85 pitch limit per game. Now, this may a good thing to do, but I have great difficulty seeing a direct connection. Here's why.
With any decision inferences (classification), there are two questions to be asked:
1) what patterns are related to the outcome of interest
2) are there differences between patterns related to the outcome of interest and those related to another outcome?
Here's my problem: I have seen no data (in the article) to indicate that pitchers today throw more pitches than boys did 10 years ago. And I see no evidence in particular that boys today throw more than 85 pitches more frequently that boys did 10 years ago. If this isn't the case, then why would the new limit have any effect at all? It can only be due to a cause that is not directly addressed here. If by limited pitches in a game (and therefore in any given week), the boys throw fewer pitches in a year, there might be an effect.
But based on the evidence that is known and not speculation, wouldn't it make more sense to limit pitchers to five months of pitching per calendar year? That after all has direct empirical evidence of tangible results.
I see this happen in the business world as well, where despite empirical evidence that indicate "Procedure A", the decision makers go with "Procedure B" for a variety of reasons unrelated to the data. And sometimes there is good reason to do so despite the data, but at least we should know that in these cases we are ignoring the data.
ENDNOTE:
I suspect one reason this strikes me is that I used to pitch on traveling teams in my Little League years, back before one cared about pitch counts (30+ years ago). I'm sure I pitched games well over 85, and probably 100+ pitches on a regular basis. One difference was that I lived in New England where you were fortunate to play March through August, and so we all had a good period of time to recover.
young pitchers who pitch more than 8 months a year are 5 times as likely to need surgery as those who pitch 5 1/2 months a year.
In San Diego, where I'm located, this can be a big problem because there is baseball going on all year round (even in Little League, where there are summer and fall leagues, plus the ever-present year-round traveling teams).
So what's the solution? A year ago or so they instituted an 85 pitch limit per game. Now, this may a good thing to do, but I have great difficulty seeing a direct connection. Here's why.
With any decision inferences (classification), there are two questions to be asked:
1) what patterns are related to the outcome of interest
2) are there differences between patterns related to the outcome of interest and those related to another outcome?
Here's my problem: I have seen no data (in the article) to indicate that pitchers today throw more pitches than boys did 10 years ago. And I see no evidence in particular that boys today throw more than 85 pitches more frequently that boys did 10 years ago. If this isn't the case, then why would the new limit have any effect at all? It can only be due to a cause that is not directly addressed here. If by limited pitches in a game (and therefore in any given week), the boys throw fewer pitches in a year, there might be an effect.
But based on the evidence that is known and not speculation, wouldn't it make more sense to limit pitchers to five months of pitching per calendar year? That after all has direct empirical evidence of tangible results.
I see this happen in the business world as well, where despite empirical evidence that indicate "Procedure A", the decision makers go with "Procedure B" for a variety of reasons unrelated to the data. And sometimes there is good reason to do so despite the data, but at least we should know that in these cases we are ignoring the data.
ENDNOTE:
I suspect one reason this strikes me is that I used to pitch on traveling teams in my Little League years, back before one cared about pitch counts (30+ years ago). I'm sure I pitched games well over 85, and probably 100+ pitches on a regular basis. One difference was that I lived in New England where you were fortunate to play March through August, and so we all had a good period of time to recover.
Wednesday, June 27, 2007
Is Data Mining Dangerous?
I've had my share of data mining mishaps, but never quite this severe...
Five Workers Trapped in Data Mining Accident
By Brian Briggs
New York, NY - Five workers were trapped in their cubicle while data mining at the research firm Thompson, Thompson and Gowhoopie. The last communication with the workers was an instant message that asked for “sandwiches from Gino's.” After that, it's believed the workers battery-back up system failed and left them without any means to contact the surface.
See the full story here.
(HT Daniele Micci-Barreca)
Five Workers Trapped in Data Mining Accident
By Brian Briggs
New York, NY - Five workers were trapped in their cubicle while data mining at the research firm Thompson, Thompson and Gowhoopie. The last communication with the workers was an instant message that asked for “sandwiches from Gino's.” After that, it's believed the workers battery-back up system failed and left them without any means to contact the surface.
See the full story here.
(HT Daniele Micci-Barreca)
Monday, June 25, 2007
To Graph Or Not To Graph
Recently, I had an interesting conversation with an associate regarding graphs. My colleague had worked with someone who held the opinion that graphs were worthless, since anything you might decide based on a graph should really be decided based on a statistic. My initial response was to reject this idea. I have used graphs a number of times in my work, and believed them to be useful, although I readily admit that in many cases, a simple numeric measure or test could have been substituted, and may have added precision to the analysis. Data visualization and related technologies are all the rage at the moment, but I wonder (despite having a nerd's appetite for computer eye-candy) whether data mining should perhaps be moving away from these human-centric tools.
Thoughts?
Thoughts?
Thursday, May 24, 2007
KDnuggets 2007 Poll
The frenzy surrounding the annual software poll KDnuggets is finally over. The results are available at:
Data Mining / Analytic Software Tools (May 2007)
A number of statistical issues have been raised regarding this particular survey, but I will highlight only one here: The survey now includes separate counts for votes cast by people who voted for a single item, and those who voted for multiple items. Partially, this is in response to "get out the vote" efforts made by some vendors.
Anyway, some interesting highlights:
1. Free tools made a good showing. In the lead among free tools: Yale (103 votes).
2. "Your Own Code" (61 votes) did respectably well.
3. Despite not having data mining-specific components, MATLAB (30 votes), which is my favorite tool, was more popular than a number of well-known commercial data mining tools.
Data Mining / Analytic Software Tools (May 2007)
A number of statistical issues have been raised regarding this particular survey, but I will highlight only one here: The survey now includes separate counts for votes cast by people who voted for a single item, and those who voted for multiple items. Partially, this is in response to "get out the vote" efforts made by some vendors.
Anyway, some interesting highlights:
1. Free tools made a good showing. In the lead among free tools: Yale (103 votes).
2. "Your Own Code" (61 votes) did respectably well.
3. Despite not having data mining-specific components, MATLAB (30 votes), which is my favorite tool, was more popular than a number of well-known commercial data mining tools.
Monday, May 07, 2007
Quotes from Moneyball
I know it took me too long to do it, but I finally have read through Moneyball and thoroughly enjoyed it. There are several quotes from it that I thought captures aspects of the data mining attitude I think should be adopted.
On a personal note, I suppose my fascination with data analysis started when I was playing baseball in Farm League, and later with playing Strat-o-matic baseball. I received all the 1972 teams, and proceeded to try to play every team's complete schedule--needless to say, I didn't get too far. But more than playing the games, what I enjoyed most of all was computing the statistics and listing the leaders in the hitting and pitching categories. Once a nerd, always a nerd...
Here is the first quote:
On a personal note, I suppose my fascination with data analysis started when I was playing baseball in Farm League, and later with playing Strat-o-matic baseball. I received all the 1972 teams, and proceeded to try to play every team's complete schedule--needless to say, I didn't get too far. But more than playing the games, what I enjoyed most of all was computing the statistics and listing the leaders in the hitting and pitching categories. Once a nerd, always a nerd...
Here is the first quote:
Intelligence about baseball statistics had become equated in the public mind with the ability to recite arcane baseball stats. What [Bill] James's wider audience had failed to understand was that the statistics were beside the point. The point was understanding; the point was to make life on earth just a bit more intelligible; and that point, somehow, had been lost. 'I wonder,' James wrote, 'if we haven't become so numbed by all these numbers that we are no longer capable of truly assimilating any knowledge which might result from them.'
Friday, May 04, 2007
PMML Deployment
I posted this question on IT Toolbox, but thought I'd post it here as well.
I'm working on a project where the company wants to score
model(s) in real time (transactional type data). They also would
like to remain vendor-independent. With these in mind, they have
considered using PMML. However, they are having a hard time
finding vendors that have a Scoring Engine that runs PMML (many
software products have this, if you want to use those products).
We want a standalone option so no matter what tool is used to be
the models, we can just drop in the PMML code and run it.
I've discussed the options of running source code (C or Java),
but they also want to be able to update models on the fly
without a recompile.
Anyone have experiences with PMML in production out there?
I'm working on a project where the company wants to score
model(s) in real time (transactional type data). They also would
like to remain vendor-independent. With these in mind, they have
considered using PMML. However, they are having a hard time
finding vendors that have a Scoring Engine that runs PMML (many
software products have this, if you want to use those products).
We want a standalone option so no matter what tool is used to be
the models, we can just drop in the PMML code and run it.
I've discussed the options of running source code (C or Java),
but they also want to be able to update models on the fly
without a recompile.
Anyone have experiences with PMML in production out there?
Tuesday, May 01, 2007
Comparison of Algorithms at PAKDD2007

At the link in the title are the results from the 11th Pacific-Asia Knowledge Discovery and Data Mining conference (PAKDD 2007). The dataset for the competition was a cross-seller dataset, but that is not of interest to me here. The interesting this is these: which algorithms did the best, and were they significantly different in their performance?
A note about the image in the post: I took the results, sorted by area under the ROC curve (AUC). The results already had color coded the groups of results (into winners, top 10 and top 20)--I changed the colors to make them more legible. I also added red-bold text to the algorithm implementations that included an ensemble (note that after I did this, I discovered that the winning Probit model was also an ensemble).
And, for those who don't want to look at the image, the top four models were as follows:
AUC.......Rank...Modeling Technique
70.01%.....1.....TreeNet + Logistic Regression
69.99%.....2.....Probit Regression
69.62%.....3.....MLP + n-Tuple Classifier
69.61%.....4.....TreeNet
First, note that all four winners used ensembles, but ensembles of 3 different algorithms: Trees (Treenet), neural networks, and probits. The differences between these results are quite small (arguably not significant, but more testing would have to take place to show this). The conclusion I draw from this then is that the ensemble is more important than the algorithm; so long as there are good predictors, variation in data used to build the models, and sufficient diversity in predictions issued by the individual models.
I have not yet looked at the individual results to see how much preprocessing was necessary for each of the techniques, however I suspect that less was needed for the TreeNet models just because of the inherent characteristics of CART-styled trees in handling missing data, outliers, and categorical/numeric data.
Second, and related to the first, is this: while I still argue that generally speaking, trees are less accurate than neural networks or SVMs, ensembles level the playing field. What surprised me the most was that logistic regression or Probit ensembles performed as well as they did. This wasn't because of the algorithm, but rather because I haven't yet been convinced that Probits or Logits consistently work well in ensembles. This is more evidence that they do (though I need to read further how they were constructed to be able to comment on why they did as well as they did).
Saturday, April 21, 2007
Data Mining Methods Poll
Interesting results of the latest KDNuggets poll on data mining methods. Interestingly, Decision Trees won the competition, followed by Clustering and Regression.
A couple of observations...
1) ensembles (Bagging and Boosting) went up. The sample size is too small to make any inferences, but this will be interesting to track over time.
2) SVMs and Neural Networks are at about the same level, though SVM usage dropped from 2006. I do wonder if SVMs will surpass neural networks as the "complex way to model accurately", but the verdict is still out on this.
A couple of observations...
1) ensembles (Bagging and Boosting) went up. The sample size is too small to make any inferences, but this will be interesting to track over time.
2) SVMs and Neural Networks are at about the same level, though SVM usage dropped from 2006. I do wonder if SVMs will surpass neural networks as the "complex way to model accurately", but the verdict is still out on this.
Tuesday, April 17, 2007
Applications of Prediction Technology
It is interesting to learn how predictive technologies are being applied. Below are links to some cases which may prove instructive as well as novel:
An Empirical Study of Machine Learning Algorithms
Applied to Modeling Player Behavior in a “First Person Shooter” Video Game, Masters thesis by Benjamin Geisler
Using Machine Learning to Break Visual Human Interaction Proofs (HIPs), by Kumar Chellapilla and Patrice Y. Simard
Spatial Clustering Of Chimpanzee Locations For Neighborhood
Identification, by Sandeep Mane, Carson Murray, Shashi Shekhar, Jaideep Srivastava and Anne Pusey
Are You HOT or NOT?, by Jim Hefner and Roddy Lindsay
Predicting Student Performance, by Behrouz Minaei-Bidgoli, Deborah A. Kashy, Gerd Kortemeyer, William F. Punch
Discrimination of Hard-to-pop Popcorn Kernels by Machine Vision and Neural Networks, by W. Yang, P. Winter, S. Sokhansanj, H. Wood and B. Crerer
Predicting habitat suitability with machine learning
models, by Marta Benito Garzón, Radim Blazek, Markus Neteler, Rut Sánchez de Dios, Helios Sainz Ollero and Cesare Furlanello
It is not necessary to read such cases from end-to-end to benefit from them. Glance through these to pick up what tips you may. Happy hunting!
An Empirical Study of Machine Learning Algorithms
Applied to Modeling Player Behavior in a “First Person Shooter” Video Game, Masters thesis by Benjamin Geisler
Using Machine Learning to Break Visual Human Interaction Proofs (HIPs), by Kumar Chellapilla and Patrice Y. Simard
Spatial Clustering Of Chimpanzee Locations For Neighborhood
Identification, by Sandeep Mane, Carson Murray, Shashi Shekhar, Jaideep Srivastava and Anne Pusey
Are You HOT or NOT?, by Jim Hefner and Roddy Lindsay
Predicting Student Performance, by Behrouz Minaei-Bidgoli, Deborah A. Kashy, Gerd Kortemeyer, William F. Punch
Discrimination of Hard-to-pop Popcorn Kernels by Machine Vision and Neural Networks, by W. Yang, P. Winter, S. Sokhansanj, H. Wood and B. Crerer
Predicting habitat suitability with machine learning
models, by Marta Benito Garzón, Radim Blazek, Markus Neteler, Rut Sánchez de Dios, Helios Sainz Ollero and Cesare Furlanello
It is not necessary to read such cases from end-to-end to benefit from them. Glance through these to pick up what tips you may. Happy hunting!
Saturday, April 14, 2007
Is Data Mining still on the rise?
Another very interesting and thoughtful take on Predictive Analytics and Data Mining from Mark Madsen can be found here. I've never met him before, but I think I'd like to since he is a TDWI kind of guy, obviously well informed, and I'll be in the same location this May in Boston teaching a data mining course at the next TDWI conference in Boston on the 17th, which is Thursday.
But back to the article...Mr. Madsen writes that Predictive Analytics
But back to the article...Mr. Madsen writes that Predictive Analytics
rated by the Executive Summit attendees as the number one item expected to have the most impact over the next several years.Well, that's good news, and I think it makes sense because most companies I deal with are just starting to use predictive analytics. There will always be the powerhouse, large companies that have large data mining teams. They make for great case studies. But we'll know that data mining has "made it" when small companies can have one person working part time doing their analytics, and being effective with it. I know several companies like this already, but it takes some investment in training to get there.
Sunday, April 08, 2007
Future Data Mining Trends
In his latest post, Sandro has a nice summary about future data mining trends here. I'm with him that being a prognosticator is not something I do a lot of, but I do have one idea that I still think will happen.
First, let me say that of the references provided by Sandro, the Tom Dietterich one is something I like very much, especially his treatment of model ensembles.
At the 1999 or 2000 KDD conference in San Diego, I think there was a roundtable discussion on the future of data mining with the particular emphasis revolving around whether or not data mining will occur inside the database or external to the database. The general consensus was that mining will move more inside the database, and I frankly agreed. This has not materialized nearly to the degree I expected, though it has progressed especially in the past couple of years with improvements to Oracle Data Miner and SQL Server 2005 Business Intelligence. (I'm not familiar with the current state of DB2 Data Warehouse Edition, and I don't think there has been much work done in recent years on the Teradata Warehouse Miner product, formerly TeraMiner).
However, most folks I know who do data mining still pull data from a datamart or warehouse, build models in a standalone app, and then push models and/or scores back up to the warehouse. I think this is going to move more and more into the warehouse either through improved software in the warehouse (like what we're seeing with Oracle and Microsoft), or, perhaps more likely, through improved interfaces to warehouse functions by standalone data mining software. For example Clementine from SPSS allows you pushback database function to the database itself rather than operating on data that has been pulled from the warehouse. This speeds up basic data processing considerably I've found. I think the latter is the more likely area of growth in data mining software and how practitioners use data mining software.
First, let me say that of the references provided by Sandro, the Tom Dietterich one is something I like very much, especially his treatment of model ensembles.
At the 1999 or 2000 KDD conference in San Diego, I think there was a roundtable discussion on the future of data mining with the particular emphasis revolving around whether or not data mining will occur inside the database or external to the database. The general consensus was that mining will move more inside the database, and I frankly agreed. This has not materialized nearly to the degree I expected, though it has progressed especially in the past couple of years with improvements to Oracle Data Miner and SQL Server 2005 Business Intelligence. (I'm not familiar with the current state of DB2 Data Warehouse Edition, and I don't think there has been much work done in recent years on the Teradata Warehouse Miner product, formerly TeraMiner).
However, most folks I know who do data mining still pull data from a datamart or warehouse, build models in a standalone app, and then push models and/or scores back up to the warehouse. I think this is going to move more and more into the warehouse either through improved software in the warehouse (like what we're seeing with Oracle and Microsoft), or, perhaps more likely, through improved interfaces to warehouse functions by standalone data mining software. For example Clementine from SPSS allows you pushback database function to the database itself rather than operating on data that has been pulled from the warehouse. This speeds up basic data processing considerably I've found. I think the latter is the more likely area of growth in data mining software and how practitioners use data mining software.
Monday, March 19, 2007
Document, Document, Document!
I recently came across a cautionary list of "worst practices", penned by Dorian Pyle, titled This Way Failure Lies. No one likes filling out paperwork, but Dorian's rule 6 for disaster makes a good point:
As opposed to purely point-and-click tools, data mining tools which include "visual programming" interfaces (Insightful Miner, KNIME, Orange) or programming languages (Fortran, C++, MATLAB) allow a certain amount of self-documentation. Unless commenting is extremely thorough, though, it is probably worth producing at least some sort of summary document, which will need to explain the purpose and basic structure of the models. As analysis indicates adjustments in your course, this document should be updated accordingly.
Rule 6. Rely on memory. Most data mining projects are simple enough that you can hold most important details in your head. There's no need to waste time in documenting the steps you take. By far, the best approach is to keep pressing the investigation forward as fast as possible. Should it be necessary to duplicate the investigation or, in the unlikely event that it's necessary to justify the results at some future time, duplicating the original investigation and recreating the line of reasoning you used will be easy and straightforward.
As opposed to purely point-and-click tools, data mining tools which include "visual programming" interfaces (Insightful Miner, KNIME, Orange) or programming languages (Fortran, C++, MATLAB) allow a certain amount of self-documentation. Unless commenting is extremely thorough, though, it is probably worth producing at least some sort of summary document, which will need to explain the purpose and basic structure of the models. As analysis indicates adjustments in your course, this document should be updated accordingly.
Tuesday, March 13, 2007
Missing Values and Special Values: The Plague of Data Analysis
Every so often, an article is published on data mining which includes a statistic like "Amount of data mining time spent preparing the data: 70%", or something similar , expressed as a pie chart. It is certainly worth the investment of time and effort at the beginning of a data mining project, to get the data cleaned up, to maximize model performance and avoid problems later on.
Two related issues is data preparation are missing values and special values. Note that some "missing values" are truly "missing values" (items for which there is a true value which is not present in the data), while others are actually special values or undefined (or at least poorly defined) values. Much has already been written about truly missing values, especially in the statistical literature. See, for instance:
Dealing with Missing Data, by Judi Scheffer
Missing data, by Thomas Lumley
Working With Missing Values, by Alan C. Acock
How can I deal with missing data in my study?, by Derrick A. Bennett
Advanced Quantitative Research Methodology, G2001, Lecture Notes: Missing Data, by Gary King
Important topics to understand and keywords to search on, if one wishes to study missing data and its treatment are: MAR ("missing at random"), MCAR ("missing completely at random"), NMAR ("not missing at random"), non-response and imputation (single and multiple).
Special values, which are not quite the same as missing values, also require careful treatment. An example I encountered recently in my work with bank account data was a collection of variables which were defined over lagged time windows, such as "maximum balance over the last 6 months" or "worst delinquency in the last 12 months".
The first issue was that the special values were not database nulls ("missing values"), but were recorded as flag values, such as -999.
The second issue was that the flag values, while consistent within individual variables, varied across this set of variables. Some variables used -999 as the flag value, others used -999.99. Still others used -99999.
The first and second issues, taken together, meant that actually detecting the special values was, ultimately, a tedious process. Even though this was eventually semi-automated, the results needed to be carefully checked by the analyst.
The third issue was the phenomenon driving the creation of special values in the first place: many accounts had not been on the system long enough to have complete lagged windows. For instance, an account which is only 4 months old has not been around long enough to accumulate 12 months worth of delinquency data. In this particular system, such accounts received the flag value. Such cases are not quite the same as data which has an actual value which is simply unrecorded, and methods for "filling-in" such holes probably would provide spurious results.
A similar issue surrounds a collection of variables which relies on some benchmark event- which may or may not have happened, such as "days since purchase" or "months since delinquency". Some accounts had never purchased anything, and others had never been delinquent. One supposes that, theoretically, such situations should have infinity recorded. In the actual data, though, they had flag values, like -999.
Simply leaving the flag values makes no sense. There are a variety of ways of dealing with such circumstances, and solutions need to be carefully chosen given the context of the problem. One possibility is to convert the original variable to one which represents, for instance, the probability of the target class (in a classification problem). A simple binning or curve-fitting procedure would act as a single-variable model of the target, and the special value would be assigned whatever probability was observed in the training data for those cases.
Many important, real circumstances will give rise to these special values. Be vigilant, and treat them with care to extract the most information from them and avoid data mining pitfalls.
Two related issues is data preparation are missing values and special values. Note that some "missing values" are truly "missing values" (items for which there is a true value which is not present in the data), while others are actually special values or undefined (or at least poorly defined) values. Much has already been written about truly missing values, especially in the statistical literature. See, for instance:
Dealing with Missing Data, by Judi Scheffer
Missing data, by Thomas Lumley
Working With Missing Values, by Alan C. Acock
How can I deal with missing data in my study?, by Derrick A. Bennett
Advanced Quantitative Research Methodology, G2001, Lecture Notes: Missing Data, by Gary King
Important topics to understand and keywords to search on, if one wishes to study missing data and its treatment are: MAR ("missing at random"), MCAR ("missing completely at random"), NMAR ("not missing at random"), non-response and imputation (single and multiple).
Special values, which are not quite the same as missing values, also require careful treatment. An example I encountered recently in my work with bank account data was a collection of variables which were defined over lagged time windows, such as "maximum balance over the last 6 months" or "worst delinquency in the last 12 months".
The first issue was that the special values were not database nulls ("missing values"), but were recorded as flag values, such as -999.
The second issue was that the flag values, while consistent within individual variables, varied across this set of variables. Some variables used -999 as the flag value, others used -999.99. Still others used -99999.
The first and second issues, taken together, meant that actually detecting the special values was, ultimately, a tedious process. Even though this was eventually semi-automated, the results needed to be carefully checked by the analyst.
The third issue was the phenomenon driving the creation of special values in the first place: many accounts had not been on the system long enough to have complete lagged windows. For instance, an account which is only 4 months old has not been around long enough to accumulate 12 months worth of delinquency data. In this particular system, such accounts received the flag value. Such cases are not quite the same as data which has an actual value which is simply unrecorded, and methods for "filling-in" such holes probably would provide spurious results.
A similar issue surrounds a collection of variables which relies on some benchmark event- which may or may not have happened, such as "days since purchase" or "months since delinquency". Some accounts had never purchased anything, and others had never been delinquent. One supposes that, theoretically, such situations should have infinity recorded. In the actual data, though, they had flag values, like -999.
Simply leaving the flag values makes no sense. There are a variety of ways of dealing with such circumstances, and solutions need to be carefully chosen given the context of the problem. One possibility is to convert the original variable to one which represents, for instance, the probability of the target class (in a classification problem). A simple binning or curve-fitting procedure would act as a single-variable model of the target, and the special value would be assigned whatever probability was observed in the training data for those cases.
Many important, real circumstances will give rise to these special values. Be vigilant, and treat them with care to extract the most information from them and avoid data mining pitfalls.
Monday, March 12, 2007
Oh the ways data visualization enlightens!
I came across a blog awhile ago by Matthew Hurst called Data Mining: Text Mining, Visualization and Social Media, but revisited it today because of a recent post on data visualization blogs. The blogs he lists are interesting, though there is another one on his side bar called Statistical Graphics (check out the animated 3-D graphic!).
It just is a reminder of how difficult a truly good visualization of data is to create. Mr. Hurst shows an example from the National Safety Council that is truly an opaque graphic, and a great example of data that is crying out for a TABLE rather than a graph. (See here for the article.) I have to admit though, it looks pretty cool. Here's the graphic--can you easily summarize the key content?

But just because a graphic is complex, doesn't make it bad. (I cite as an example the graphic I posted on here.
It just is a reminder of how difficult a truly good visualization of data is to create. Mr. Hurst shows an example from the National Safety Council that is truly an opaque graphic, and a great example of data that is crying out for a TABLE rather than a graph. (See here for the article.) I have to admit though, it looks pretty cool. Here's the graphic--can you easily summarize the key content?

But just because a graphic is complex, doesn't make it bad. (I cite as an example the graphic I posted on here.
Model Selection Poll Closed
The poll is closed, with votes as follows:
R^2 or MSE 21%
Lift or Gains 46%
True Alert
vs. False Alert Tradeoff 12%
PCC 12%
Other 8%
Broken down in another way:
Global error (R^2 or PCC): 33%
Ranked error (Lift, ROC): 58%
where ranked error means that one first sorts the scored records and then scores the model. The relative proportions of these two roughly correspond to what I see and use in consulting: probably about 75% of the time I used something like ROC or Lift to score models.
Thanks to those who voted.
R^2 or MSE 21%
Lift or Gains 46%
True Alert
vs. False Alert Tradeoff 12%
PCC 12%
Other 8%
Broken down in another way:
Global error (R^2 or PCC): 33%
Ranked error (Lift, ROC): 58%
where ranked error means that one first sorts the scored records and then scores the model. The relative proportions of these two roughly correspond to what I see and use in consulting: probably about 75% of the time I used something like ROC or Lift to score models.
Thanks to those who voted.
Wednesday, February 21, 2007
Is Data Mining Too Complicated?
I just read an interesting post on Infoworld entitled Data Mining Donald. In it there is a very interesting comment, and I quote:
Before I comment further, I'll just open it up to any commenters here. There are other very interesting and important parts of the post as well.
Data mining is the future, and as of yet, it's still far too complicated for the ordinary IT guy to grasp.Is this so? If data mining is too complicated for the typical IT guy, is it also too complicated for the typical grunt analyst?
Before I comment further, I'll just open it up to any commenters here. There are other very interesting and important parts of the post as well.
Friday, February 16, 2007
Another Perspective on Data Mining and Terrorism
Recently, much has written specifically about data mining's likely usefulness as a defense against terrorism. This posting takes "data mining" to mean a sophisticated and rigorous statistical analysis, and excludes data gathering functions. Privacy issues aside, claims have recently been made regarding data mining's technical capabilities as a tool in combating terrorism.
Very specific technical assertions have been made by other experts in this field, to the effect that predictive modeling is unlikely to provide a useful identification of individuals imminently carrying out physical attacks. The general reasoning has been that, despite the magnitude of their tragic handiwork, there have been too few positive instances for accurate model construction. As far as this specific assertion goes, I concur.
Unfortunately, this notion has somehow been expanded in the press, and in the on-line writings of authors who are not expert in this field. The much broader claim has been made that "data mining cannot help in the fight against terrorism because it does not work". Such overly general statements are demonstrably false. For example, a known significant component of international terrorism is its financing, notably through its use of money laundering, tax evasion and simple fraud. These financial crimes have been under attack by data mining for over 10 years.
Further, terrorist organizations, like other human organizations, involve human infrastructure. Behind the man actually conducting the attack stands a network of support personnel: handlers, trainers, planners and the like. I submit that data mining might be useful in identifying these individuals, given their much larger number. Whether or not this would work in practice could only be known by actually trying.
Last, the issues surrounding data mining's ability to tackle the problem of terrorism have frequently been dressed up in technical language by reference to the concepts of "false positives" and "false negatives", which I believe to be a straw-man argument. Solutions to classification problems frequently involve the assessment of probabilities, rather than simple "terrorist" / "non-terrorist" outputs. The output of data mining in this case should not be used as a replacement of the judicial branch, but as a guide: Estimated probabilities can be used to prioritize, rather than condemn, individuals under scrutiny.
Very specific technical assertions have been made by other experts in this field, to the effect that predictive modeling is unlikely to provide a useful identification of individuals imminently carrying out physical attacks. The general reasoning has been that, despite the magnitude of their tragic handiwork, there have been too few positive instances for accurate model construction. As far as this specific assertion goes, I concur.
Unfortunately, this notion has somehow been expanded in the press, and in the on-line writings of authors who are not expert in this field. The much broader claim has been made that "data mining cannot help in the fight against terrorism because it does not work". Such overly general statements are demonstrably false. For example, a known significant component of international terrorism is its financing, notably through its use of money laundering, tax evasion and simple fraud. These financial crimes have been under attack by data mining for over 10 years.
Further, terrorist organizations, like other human organizations, involve human infrastructure. Behind the man actually conducting the attack stands a network of support personnel: handlers, trainers, planners and the like. I submit that data mining might be useful in identifying these individuals, given their much larger number. Whether or not this would work in practice could only be known by actually trying.
Last, the issues surrounding data mining's ability to tackle the problem of terrorism have frequently been dressed up in technical language by reference to the concepts of "false positives" and "false negatives", which I believe to be a straw-man argument. Solutions to classification problems frequently involve the assessment of probabilities, rather than simple "terrorist" / "non-terrorist" outputs. The output of data mining in this case should not be used as a replacement of the judicial branch, but as a guide: Estimated probabilities can be used to prioritize, rather than condemn, individuals under scrutiny.
Tuesday, February 06, 2007
Quote of the day
"[Statistics] means never having to say you're sure."
I first heard this from John Elder, and it is documented here where John presented an summary of the Symposium on the Interface conference for SIGKDD Explorations (Jun06), though I think he gave the talk initially at KDD-98.
John doesn't name who said it though, and have never heard him name the person. Maybe so many have said it, that it is just one of those anonymous quotes that is ubiquitous, but in a quick search, the only place I found it was as a reference--in the title of a talk at a Fisheries conference:
Hayes, D. B., and J.R. Bence. Managing under uncertainty, or, statistics is never having to say you’re sure. Michigan Chapter of the American Fisheries Society, East Lansing, MI. 1996.
I first heard this from John Elder, and it is documented here where John presented an summary of the Symposium on the Interface conference for SIGKDD Explorations (Jun06), though I think he gave the talk initially at KDD-98.
John doesn't name who said it though, and have never heard him name the person. Maybe so many have said it, that it is just one of those anonymous quotes that is ubiquitous, but in a quick search, the only place I found it was as a reference--in the title of a talk at a Fisheries conference:
Hayes, D. B., and J.R. Bence. Managing under uncertainty, or, statistics is never having to say you’re sure. Michigan Chapter of the American Fisheries Society, East Lansing, MI. 1996.
Monday, February 05, 2007
Poll: Model Selection
In the spirit of the latest posts on model selection, here is a poll to get feedback on that question. I understand that few practitioners always use the exact same metric to select models. This poll is only asking which one is used most often when you need a single number to select models (and input variables don't matter as much).

Thursday, February 01, 2007
When some models are signficantly better than others
I'm not a statistician, nor have I played one on TV. That’s not to say I’m not a big fan of statistics. In the age-old debate between data mining and statistics, there is much to say on both sides of the aisle. While much of this kind of debate I find unnecessary, and conflicts have arisen as much over terminology rather than the actual concepts, there are some areas where I have found a sharp divide.
One of these areas is the idea of significance. Most statisticians who excel in their craft that I have spoken with are well-versed in discussions of p-values, t-values, and confidence intervals. Most data miners, on the other had, have probably never heard of these, or even if they have, never use them. Aside from the good reasons to use or not use these kind of metrics, I think it typifies an interesting phenomenon in the data mining world, which is the lack of measures of significance. I want to consider that issue in the context of model selection: how does one assess whether or not two models are different enough so that there are compelling reasons to select one over the other?
One example of this is what one sees when using a tool like Affinium Model (Unica Corporation)—a tool I like to use very much. If you are building a binary classification model, it will build for you, automatically, dozens, hundreds, potentially even thousands of models of all sorts (regression, neural networks, C&RT trees, CHAID trees, Naïve Bayes). After the models have been built, you get a list of the best models, sorted by whatever metric you have decided (typically area under the lift curve or response rate at a specified file depth). All of this is great. The table below shows a sample result:
Model.........Rank..Total Lift....Algorithm
NeuralNet1131...1....79.23%....Backpropagation Neural Network
NeuralNet1097...2....79.20%....Backpropagation.Neural.Network
NeuralNet1136...3....79.18%....Backpropagation.Neural.Network
NeuralNet1117...4....79.10%....Backpropagation.Neural.Network
NeuralNet1103...5....79.09%....Backpropagation.Neural.Network
Logit774........6....78.91%....Logistic.Regression
Bayes236........7....78.50%....Naive Bayes
LinReg461.......8....78.48%....Linear.Regression
CART39..........9....75.75%....CART
CHAID5.........10....75.27%....CHAID
Yes, the Neural Network model (NeuralNet1131) has won the competition and has the best total lift. But the question is this: is it significantly better than the other models? (Yes, linear regression was one of the options for a binary classification model—and this is a good thing, but a topic for another day). How much improvement is significant? There is no significance test applied here to tell us this. (to be continued…)
One of these areas is the idea of significance. Most statisticians who excel in their craft that I have spoken with are well-versed in discussions of p-values, t-values, and confidence intervals. Most data miners, on the other had, have probably never heard of these, or even if they have, never use them. Aside from the good reasons to use or not use these kind of metrics, I think it typifies an interesting phenomenon in the data mining world, which is the lack of measures of significance. I want to consider that issue in the context of model selection: how does one assess whether or not two models are different enough so that there are compelling reasons to select one over the other?
One example of this is what one sees when using a tool like Affinium Model (Unica Corporation)—a tool I like to use very much. If you are building a binary classification model, it will build for you, automatically, dozens, hundreds, potentially even thousands of models of all sorts (regression, neural networks, C&RT trees, CHAID trees, Naïve Bayes). After the models have been built, you get a list of the best models, sorted by whatever metric you have decided (typically area under the lift curve or response rate at a specified file depth). All of this is great. The table below shows a sample result:
Model.........Rank..Total Lift....Algorithm
NeuralNet1131...1....79.23%....Backpropagation Neural Network
NeuralNet1097...2....79.20%....Backpropagation.Neural.Network
NeuralNet1136...3....79.18%....Backpropagation.Neural.Network
NeuralNet1117...4....79.10%....Backpropagation.Neural.Network
NeuralNet1103...5....79.09%....Backpropagation.Neural.Network
Logit774........6....78.91%....Logistic.Regression
Bayes236........7....78.50%....Naive Bayes
LinReg461.......8....78.48%....Linear.Regression
CART39..........9....75.75%....CART
CHAID5.........10....75.27%....CHAID
Yes, the Neural Network model (NeuralNet1131) has won the competition and has the best total lift. But the question is this: is it significantly better than the other models? (Yes, linear regression was one of the options for a binary classification model—and this is a good thing, but a topic for another day). How much improvement is significant? There is no significance test applied here to tell us this. (to be continued…)
Sunday, January 28, 2007
Data Mining Acceptance
Dean has written recently about confusion surrounding the term "data mining" (see his Jan-11-2007 posting, Will the term "Data Mining" survive?). Clearly, this has muddled much of the debate surrounding things like the privacy and security implications of data mining by government.
Setting other definitions aside, though, there remain issues of data mining acceptance in the world of business. A short, interesting item on this subject is Sam Batterman's's Jan-19-2007 posting, Interesting Thread on Why Data Mining (DM) is not used more in business. My response, which is in the Comments section there, is:
"While it is frequently lamented that technology advances much more quickly than government, especially law enforcement and the judiciary, it is clearly the case that businesses are only better by comparison. Even in industries with a long-established and accepted need for sophisticated statistical anlysis, managers display a shocking lack of understanding of what is possible with newer tools from fields like data mining. Further, this ignorance is not the exclusive domain of executive or senior management, who are somewhat removed from the people and systems which perform data mining. Managers whose immediate subordinates do the actual data mining frequently require education, as any statistical knowledge they possess seems typically stuck in the late 1970s. In my experience, upward lobbying efforts on the part of the data miner are only sometimes effective. The argument to recalcitrant management which I have found most effective is "If we only do what you did at your last company, and what everyone else in the industry is doing, where will our competitive advantage come from?" Sadly, it is my expectation that data mining will only catch on in individual industries after some intrepid manager demonstrates conclusively the money that data mining can return, and the others follow like sheep."
I'd be curious to learn what readers' thoughts on this are.
Setting other definitions aside, though, there remain issues of data mining acceptance in the world of business. A short, interesting item on this subject is Sam Batterman's's Jan-19-2007 posting, Interesting Thread on Why Data Mining (DM) is not used more in business. My response, which is in the Comments section there, is:
"While it is frequently lamented that technology advances much more quickly than government, especially law enforcement and the judiciary, it is clearly the case that businesses are only better by comparison. Even in industries with a long-established and accepted need for sophisticated statistical anlysis, managers display a shocking lack of understanding of what is possible with newer tools from fields like data mining. Further, this ignorance is not the exclusive domain of executive or senior management, who are somewhat removed from the people and systems which perform data mining. Managers whose immediate subordinates do the actual data mining frequently require education, as any statistical knowledge they possess seems typically stuck in the late 1970s. In my experience, upward lobbying efforts on the part of the data miner are only sometimes effective. The argument to recalcitrant management which I have found most effective is "If we only do what you did at your last company, and what everyone else in the industry is doing, where will our competitive advantage come from?" Sadly, it is my expectation that data mining will only catch on in individual industries after some intrepid manager demonstrates conclusively the money that data mining can return, and the others follow like sheep."
I'd be curious to learn what readers' thoughts on this are.
Saturday, January 13, 2007
Do and Do Not
There's too many men, too many people making too many problems, and not much love to go 'round. Can't you see? This is the land of confusion.
-Genesis, Land of Confusion
In my travels, I have encountered a wide variety of people who use mathematics to analyze data and make predictions. They go by a variety of titles and work in many different fields. My first job out of college was working in an econometrics group for the Port Authority of New York and New Jersey, in the Twin Towers. The emphasis there was on traditional econometric techniques. Later in my career, I worked as a consultant for SKF, a large manufacturing firm, with engineers who emphasized quality control techniques. Most recently, I have been working with bankers doing credit scoring and the like. Surprise, surprise: the bankers have their own way of doing things, too. I won't bore the reader with the myriad other diverse quantitative analysts I've met in between, because you probably already get the idea.
These industry-specific sub-disciplines of analysis developed largely in isolation and, unfortunately, most are quite parochial. For the most part, technique has become stagnant, reflecting old rules of thumb which are outdated, if they weren't invalid in the first place.
Many people say that data mining (modeling, forecasting, etc.) are "part art, part science". I agree, but the science should give parameters to the art. Creativity in the combined discipline of quantitative model-building does not give license to venture beyond the absolutes that statistical science has provided. From this perspective, there are some things which should always be practiced, and some which should never be practiced: Do and Do Not: Everything in between is up to the taste of the analyst.
Sadly, many practitioners and even entire industries have become arthritic by establishing new, would-be "absolutes" beyond the dictates of probability theory. Some of these rules attempt to expand the Do by setting capricious limits on modeling which are not theoretically justified. The Director of risk management at one credit card company once told me that a "good" model had about 8 or 10 inputs. Naturally, that is nonsense. The number of input variables should be determined by the data via appropriate testing, not some rule-of-thumb. Others of these rules try to expand the Do Not by prohibiting practices which are well established by both theory and experiment.
As a data miner ("statistician", "econometrician", "forecaster", "meteorologist", "quality technician", "direct marketer", etc.), it is one's responsibility to continue to study the latest literature to understand how the collective knowledge of Do and Do Not have progressed. This is the only way to avoid arbitrary processes which both hold back empirical modeling and push it to make serious mistakes.
-Genesis, Land of Confusion
In my travels, I have encountered a wide variety of people who use mathematics to analyze data and make predictions. They go by a variety of titles and work in many different fields. My first job out of college was working in an econometrics group for the Port Authority of New York and New Jersey, in the Twin Towers. The emphasis there was on traditional econometric techniques. Later in my career, I worked as a consultant for SKF, a large manufacturing firm, with engineers who emphasized quality control techniques. Most recently, I have been working with bankers doing credit scoring and the like. Surprise, surprise: the bankers have their own way of doing things, too. I won't bore the reader with the myriad other diverse quantitative analysts I've met in between, because you probably already get the idea.
These industry-specific sub-disciplines of analysis developed largely in isolation and, unfortunately, most are quite parochial. For the most part, technique has become stagnant, reflecting old rules of thumb which are outdated, if they weren't invalid in the first place.
Many people say that data mining (modeling, forecasting, etc.) are "part art, part science". I agree, but the science should give parameters to the art. Creativity in the combined discipline of quantitative model-building does not give license to venture beyond the absolutes that statistical science has provided. From this perspective, there are some things which should always be practiced, and some which should never be practiced: Do and Do Not: Everything in between is up to the taste of the analyst.
Sadly, many practitioners and even entire industries have become arthritic by establishing new, would-be "absolutes" beyond the dictates of probability theory. Some of these rules attempt to expand the Do by setting capricious limits on modeling which are not theoretically justified. The Director of risk management at one credit card company once told me that a "good" model had about 8 or 10 inputs. Naturally, that is nonsense. The number of input variables should be determined by the data via appropriate testing, not some rule-of-thumb. Others of these rules try to expand the Do Not by prohibiting practices which are well established by both theory and experiment.
As a data miner ("statistician", "econometrician", "forecaster", "meteorologist", "quality technician", "direct marketer", etc.), it is one's responsibility to continue to study the latest literature to understand how the collective knowledge of Do and Do Not have progressed. This is the only way to avoid arbitrary processes which both hold back empirical modeling and push it to make serious mistakes.
Thursday, January 11, 2007
Will the term "Data Mining" survive?
I used to argue that data mining as a field will survive because it was tied so much to the bottom line--CFOs and stakeholders were involved with data mining applications and therefore the field would avoid the hype that crippled neural networks, AI and prior pattern recognition-like technologies. These achieved buzzword status that unfortunately surpassed successful practical applications.
However, it appears that the term data mining is being tied more and more to the process of data collection from multiple sources (and the subsequent analysis of that data), such as here and here and here. I try to argue with critics that the real problem is not with the algorithms, but with the combining of the data sets to begin with. Once the data is joined, whether you use data mining, OLAP, or just simple Excel reports, there is a possible privacy concern. Data mining per se has little to do with this; it only can be used to describe what data is there.
However, the balance may be tipping. Data mining (whether related to government programs or internet cookies) has become the term associated with all that is bad about combining personal information sources so that its days I think are numbered. Maybe it's time to move on to the next term or phrase, and then the next phrase, and so on, and so on, and so on...
However, it appears that the term data mining is being tied more and more to the process of data collection from multiple sources (and the subsequent analysis of that data), such as here and here and here. I try to argue with critics that the real problem is not with the algorithms, but with the combining of the data sets to begin with. Once the data is joined, whether you use data mining, OLAP, or just simple Excel reports, there is a possible privacy concern. Data mining per se has little to do with this; it only can be used to describe what data is there.
However, the balance may be tipping. Data mining (whether related to government programs or internet cookies) has become the term associated with all that is bad about combining personal information sources so that its days I think are numbered. Maybe it's time to move on to the next term or phrase, and then the next phrase, and so on, and so on, and so on...
Special Issue on Data Mining
The International Journal of Computer Applications has a new issue out on data mining applications. I didn't recognize anyone on the list of authors, but there was an interesting looking paper on a new boosting algorithm applied to intrusion detection (and using the KDDCup 99 intrusion detection data set, they claim it was better than the winning algorithm).
(HT Inderscience News)
(HT Inderscience News)
Viewing PPT created on Mac on a PC
I know this isn't about data mining, but I had to vent on this one...
So my daughter created a PPT presentation on a mac, and I tried to print it to a printer from my laptop. We copied the file over to my PC, and I got the dreaded "QuickTime and a TIFF (LZW) decompressor are needed to see this picture" error for all the graphics. I do a google search, and most of the solutions are "you messed up doing drag&drop on your mac--you MUST save the images to a file and then do a Picture->From File import of the images into the presentation". Now I've messed with computers for a lot of years, and this just isn't the way things should be done. The other solutions were things like "create a web page, uncompress the compressed images, and then reimport the images into PPT". Well, it's already 1am and I'm not in much of a mood to redo my daughter's presentation (while she blissfully sleeps).
So, there's another solution (There had to be an easier way). I just exported the file on the mac as a TIFF file (multipage). Voila-it saves all the images as ...well...TIFF (probably not some funky image format within the TIFF wrapper) rather than compressed PICT and it worked like a charm. (I suspect that there are other exports that would work as well). Now why wasn't that on the web as a solution....?
So my daughter created a PPT presentation on a mac, and I tried to print it to a printer from my laptop. We copied the file over to my PC, and I got the dreaded "QuickTime and a TIFF (LZW) decompressor are needed to see this picture" error for all the graphics. I do a google search, and most of the solutions are "you messed up doing drag&drop on your mac--you MUST save the images to a file and then do a Picture->From File import of the images into the presentation". Now I've messed with computers for a lot of years, and this just isn't the way things should be done. The other solutions were things like "create a web page, uncompress the compressed images, and then reimport the images into PPT". Well, it's already 1am and I'm not in much of a mood to redo my daughter's presentation (while she blissfully sleeps).
So, there's another solution (There had to be an easier way). I just exported the file on the mac as a TIFF file (multipage). Voila-it saves all the images as ...well...TIFF (probably not some funky image format within the TIFF wrapper) rather than compressed PICT and it worked like a charm. (I suspect that there are other exports that would work as well). Now why wasn't that on the web as a solution....?
Wednesday, January 10, 2007
Data Visualization: the good, the bad, and the complex
I have found that data visualization for the purposes of explaining results is often done poorly. I am not a fan of the pie chart, for example, and am nearly always against the use of 3-D charts when shown on paper or a computer screen (where it appears as a 2-D entity anyway). With that said, that doesn't mean that charts and graphs need to be boring. If you would like to see some interesting examples of obtuse charts and figures, go Stephen Few's web site to look at the examples--they are very interesting.
I like in particular this one, which also contains a good example of humility on the part of the chart designer, along with their improvement on the original.
However, even well-designed charts are not always winners if they don't communicate the ideas effectively to the intended audience. One of my favorite charts in my work was for a health club is on my web site, and is reproduced here:

The question here was this: based on survey given to members of the clubs, which characteristics expressed in the survey were most related to the members with the highest value? I have always liked it because it has a combination of simplicity (it is easy to see the balls and understand that higher is better for each of them, showing which characteristics for the club are better than the peer average), yet it is rich with information. There are at least four dimensions of information (arguably six). The figure of merit for judging 'good' is a combination of questions on the club survey related to overall satisfaction, likelihood to recommend the club to a friend, and the individual's interest in renewing members--this was called the 'Index of Excellence'
Each bullet was a dimension represented in the plot, but note that bullets 2 and 3 were relative values and really represent two dimensions. Regardless of how many dimensions you would count, the chart I think is visually appealing and information rich. One could simplify it by removing the small dots, but that's about all I would do to it. My web site also has this picture there, but it was recolored to fit the color scheme of the web site, and I think it loses some of its visual intuitive feel as a result.
However, much to my dismay, the end customer found it too complex, and we (Seer Analytics, LLC and I) created another rule-based solution that turned out to be more appealing.
Opinions on the graphic are appeciated as well--maybe Seer and I just missed something here :) But at this point it is all academic anyway since the time for modifying this solution has long passed.
I like in particular this one, which also contains a good example of humility on the part of the chart designer, along with their improvement on the original.
However, even well-designed charts are not always winners if they don't communicate the ideas effectively to the intended audience. One of my favorite charts in my work was for a health club is on my web site, and is reproduced here:

The question here was this: based on survey given to members of the clubs, which characteristics expressed in the survey were most related to the members with the highest value? I have always liked it because it has a combination of simplicity (it is easy to see the balls and understand that higher is better for each of them, showing which characteristics for the club are better than the peer average), yet it is rich with information. There are at least four dimensions of information (arguably six). The figure of merit for judging 'good' is a combination of questions on the club survey related to overall satisfaction, likelihood to recommend the club to a friend, and the individual's interest in renewing members--this was called the 'Index of Excellence'
- seven most significant survey questions are plotted in order right to left (rightmost is the most important). Signficance was determine by a combination of factor analysis and linear regression models
- the relative performance of each club compared to the others in its peer group is shown by the y-axis, with the average of clubs.
- the relative difference between results from the year 2003 and 2002 are shown in two ways: first with the color of the ball (green for better, yellow for about the same, and red for worse), and also by comparing the big ball to the dot in the same relative position (up and down) in the importance axis.
- finally, the size of the ball indicated the relative importance of the survey question for that club--bigger meant more important.
Each bullet was a dimension represented in the plot, but note that bullets 2 and 3 were relative values and really represent two dimensions. Regardless of how many dimensions you would count, the chart I think is visually appealing and information rich. One could simplify it by removing the small dots, but that's about all I would do to it. My web site also has this picture there, but it was recolored to fit the color scheme of the web site, and I think it loses some of its visual intuitive feel as a result.
However, much to my dismay, the end customer found it too complex, and we (Seer Analytics, LLC and I) created another rule-based solution that turned out to be more appealing.
Opinions on the graphic are appeciated as well--maybe Seer and I just missed something here :) But at this point it is all academic anyway since the time for modifying this solution has long passed.
Tuesday, January 09, 2007
Free Data Mining Software Poll Results, and notes on Sample Size
I inadvertantly closed the poll, couldn't figure out how to reopen it, and since it was already up a week, I decided that I will leave it closed.
The results are:
WEKA: 11 (55%)
YALE: 4 (20%)
R: 3 (15%)
Custom: 1 (5%)
Other: 1 (5%)
Total Votes: 20
But is there anything signficant? Is WEKA signficantly more popular than YALE or R? Well, this is outside of my expertise--after all, the word "signficant" is rarely used in data mining circles :)--but it seems to me that the answer is "yes". Why?
By starting with the standard sample size formula, and using the WEKA percentage as the hypothesis (55%, or 0.55), we are only 68% confident that this 55% can be achieved with a sample size of 25 (larger than I used). So it is therefore not a particularly significant finding that WEKA is not more popular than the other tools.
Plugging in the numbers for just WEKA and YALE (if that were the extent of the survey, forcing everyone to vote between just those two, which of course did not happen, but play along for a bit...), where the difference was 55% to 20%, we find that for a sample sizes of 15 (11 votes + 4 vote), we would have been more than 99% confident that the 55% +/- 35% can be achieved.
I'll try another poll once the numbers coming to this blog go up a bit. Thanks for participating!
The results are:
WEKA: 11 (55%)
YALE: 4 (20%)
R: 3 (15%)
Custom: 1 (5%)
Other: 1 (5%)
Total Votes: 20
But is there anything signficant? Is WEKA signficantly more popular than YALE or R? Well, this is outside of my expertise--after all, the word "signficant" is rarely used in data mining circles :)--but it seems to me that the answer is "yes". Why?
By starting with the standard sample size formula, and using the WEKA percentage as the hypothesis (55%, or 0.55), we are only 68% confident that this 55% can be achieved with a sample size of 25 (larger than I used). So it is therefore not a particularly significant finding that WEKA is not more popular than the other tools.
Plugging in the numbers for just WEKA and YALE (if that were the extent of the survey, forcing everyone to vote between just those two, which of course did not happen, but play along for a bit...), where the difference was 55% to 20%, we find that for a sample sizes of 15 (11 votes + 4 vote), we would have been more than 99% confident that the 55% +/- 35% can be achieved.
I'll try another poll once the numbers coming to this blog go up a bit. Thanks for participating!
Tuesday, January 02, 2007
First Poll--Free data mining software
Just trying this to see what comes out of it. Make sure you scroll down to see all seven entries: R, Other, Orange, Xelopes, YALE, WEKA, Custom. I didn't include matlab knockoffs or Matlab toolboxes (like SVM-light)
Monday, January 01, 2007
For the Best Answer, Ask the Best Question
A subject of great interest to data mining novices is the selection of data mining software. Frequently these interests are expressed in terms of what is "the best" software to buy. On-line, such queries are often met with quick and eager responses (and not just from vendors). In a way, this mimics the much more common (and much more incendiary) question about which programming language is "the best".
Not withstanding myriad fast answers, the answer to such questions is, of course, "It depends". What is the problem you are trying to solve? What is your familiarity with any of the available alternatives? How large is your budget? How large is your budget for ongoing subscription costs? How do you intend to deploy the result of your data mining effort?
Vendors, naturally, have an incentive to emphasize any feature which they believe will move product. Some vendors are worse about this than others. Years ago, one neural network shell vendor touted the fact that their software used "32-bit math", without ever demonstrating the benefit of this feature. In truth, competing software, which ran 16-bit fixed-point arithmetic was much faster, gave accurate results, and did not require 32-bit hardware.
The problem of irrelevant features is exacerbated by the presence of individuals in the customer organization who buy into this stuff. Some use this as political leverage on their unaware peers. I attended in a vendor presentation once with a banking client in which one would-be expert asked whether the vendor's computers were SIMD or MIMD. This was like asking whether the vendor's cafeteria served this or that brand of coffee and could not have been less relevant to the conversation. The asking of such a question was clearly a power play and served only as a distraction.
When confronted with unfamiliar features, my recommendation is to ask as many questions as it takes to understand why said features are of benefit. Don't stop with the vendor. Ask associates at other firms what they know about the subject. Try on-line discussion groups. Keep asking "Why?" until you are satisfied. Joe Pesci's character in "My Cousin Vinny" is a good model: "Why does SIMD vs. MIMD matter?" "Is one better than the other?" "Exactly how is it better?" "Is it faster? How much faster?" "Does it cost more?" Remember that diligence is the responsibility of the customer.
Some things to consider when framing the question "What is the best data mining software for my purposes?":
-Up front software cost
-Up front hardware cost, if any
-Continuing software costs (subscription prices)
-Training time for users
-Algorithms which match your needs
-Effective data capacity in variables
-Effective data capacity in examples
-Testing capabilities
-Model deployment options (source code, libraries, etc.)
-Model deployment costs (licensing costs, if any)
-Ease of interface with your data sources
-Ability to deal with missing values, special values, outliers, etc.
-Data preparation capabilities (generation of derived or transformed variables)
-Automatic attribute selection / Data reduction
Not withstanding myriad fast answers, the answer to such questions is, of course, "It depends". What is the problem you are trying to solve? What is your familiarity with any of the available alternatives? How large is your budget? How large is your budget for ongoing subscription costs? How do you intend to deploy the result of your data mining effort?
Vendors, naturally, have an incentive to emphasize any feature which they believe will move product. Some vendors are worse about this than others. Years ago, one neural network shell vendor touted the fact that their software used "32-bit math", without ever demonstrating the benefit of this feature. In truth, competing software, which ran 16-bit fixed-point arithmetic was much faster, gave accurate results, and did not require 32-bit hardware.
The problem of irrelevant features is exacerbated by the presence of individuals in the customer organization who buy into this stuff. Some use this as political leverage on their unaware peers. I attended in a vendor presentation once with a banking client in which one would-be expert asked whether the vendor's computers were SIMD or MIMD. This was like asking whether the vendor's cafeteria served this or that brand of coffee and could not have been less relevant to the conversation. The asking of such a question was clearly a power play and served only as a distraction.
When confronted with unfamiliar features, my recommendation is to ask as many questions as it takes to understand why said features are of benefit. Don't stop with the vendor. Ask associates at other firms what they know about the subject. Try on-line discussion groups. Keep asking "Why?" until you are satisfied. Joe Pesci's character in "My Cousin Vinny" is a good model: "Why does SIMD vs. MIMD matter?" "Is one better than the other?" "Exactly how is it better?" "Is it faster? How much faster?" "Does it cost more?" Remember that diligence is the responsibility of the customer.
Some things to consider when framing the question "What is the best data mining software for my purposes?":
-Up front software cost
-Up front hardware cost, if any
-Continuing software costs (subscription prices)
-Training time for users
-Algorithms which match your needs
-Effective data capacity in variables
-Effective data capacity in examples
-Testing capabilities
-Model deployment options (source code, libraries, etc.)
-Model deployment costs (licensing costs, if any)
-Ease of interface with your data sources
-Ability to deal with missing values, special values, outliers, etc.
-Data preparation capabilities (generation of derived or transformed variables)
-Automatic attribute selection / Data reduction
Subscribe to:
Posts (Atom)







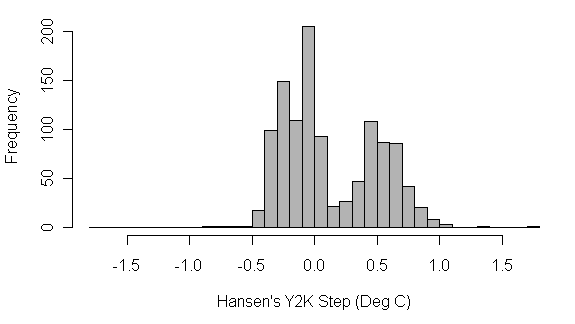{kind=link}