At MineThatData blog there is a very interesting post on email marketing productivity was very interesting, and a good example of Simpson's Paradox (as I posted in the comments). The key (as always) is that there are disproportionate population sizes with quite disparate results. As Kevin points out in the post, there is a huge difference between the profit due to engaged customers vs. those who aren't engaged, but the number of non-engaged customers dwarfs the engaged.
The problem we all have in analytics is finding these effects--unless you create the right features, you never see it. To create good features, you usually need to have moderate to considerable expertise in the domain area to know what might be interesting. And yes, neural networks can find these effects automatically, but you still have to back out the relationships between the features found by the NNets and the original inputs in order to interpret the results.
Nevertheless, this is a very important post if for no other reason but to alert practitioners that relative sizes of groups of customers (or other natural groupings in the data) matter tremendously.
Friday, August 31, 2007
Tuesday, August 21, 2007
Little League pitch counts -- data vs decisions revisited
I posted recently on the new rules in pitch counts for Little League. I've had to defend my comments recently (in a polite way on this blog, and a bit more strenuously in person with friends who have sons pitching in LL), but was struck again about this issue while watching the LL World Series on ESPN.
On the ESPN web site I read this article on pitch counts, and found this comment on point:
In other words, coaches know that it isn't pitch counts per se that cause the problems, but rather the number of months of the year the kids are pitching.
Interestingly, there is no ban on breaking pitches, though when I talk to coaches, there is speculation that these cause arm problems. In fact, on the Little League web site, they state:
I'm glad they are studying it, but the decision not to act to ban breaking pitches due to a lack of data is interesting since there is also a lack of data with pitch counts, but it didn't stop the officials from making rules there! Hopefully with the new pitch count rules, and the new data collected, we can see of the data bears out this hypothesis.
On the ESPN web site I read this article on pitch counts, and found this comment on point:
What's interesting here is that the 20-pitch specialist is the residue of a change that did not, strictly speaking, emanate from problems within Little League itself. Around the coaching community, it is widely understood that the advent of nearly year-round travel (or "competitive") ball is one of the primary reasons for the rise in young arm problems. In some ways, Little League has made a pitch-count adjustment in reaction to forces that are beyond its control.
Travel ball has become an almost de facto part of a competitive player's baseball life -- just as it has in soccer, basketball and several other youth sports. An alphabet soup of sponsoring organizations, from AAU to USSSA, BPA and well beyond, offers the opportunity to play baseball at levels -- and sheer numbers of games -- that a previous generation of players would have found mind-boggling.
But travel ball is here to stay -- and so too, apparently, is a new approach by Little League to containing the potential damage to young arms. So get used to the 20-pitch kid. He's a closer on the shortest leash imaginable.
In other words, coaches know that it isn't pitch counts per se that cause the problems, but rather the number of months of the year the kids are pitching.
Interestingly, there is no ban on breaking pitches, though when I talk to coaches, there is speculation that these cause arm problems. In fact, on the Little League web site, they state:
While there is no medical evidence to support a ban on breaking pitches, it is widely speculated by medical professionals that it is ill-advised for players under 14 years old to throw breaking pitches,” Mr. Keener said. “Breaking pitches for these ages continues to be strongly discouraged by Little League, and that is an issue we are looking at as well. As with our stance on pitch counts, we will act if and when there is medical evidence to support a change.
I'm glad they are studying it, but the decision not to act to ban breaking pitches due to a lack of data is interesting since there is also a lack of data with pitch counts, but it didn't stop the officials from making rules there! Hopefully with the new pitch count rules, and the new data collected, we can see of the data bears out this hypothesis.
Wednesday, August 15, 2007
KDNuggets Poll on "Data Mining" as a term
KDNuggets has a new poll on whether or not "data mining" should still be used to describe the kind of analysis we all know and love. It is still barely winning, but interesting, Knowledge Discovery is almost beating it out as the better term.
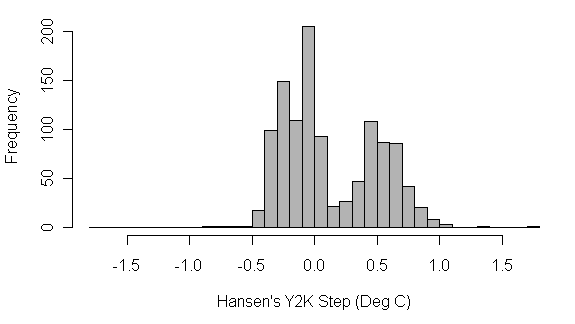
The latest Y2K bug--and why mean values don't tell the whole story
I was interested in the recent hubbub over surface temperatures as first written in NASA's Daily Tech, and picked up by other news sources. (Note: the article doesn't render well for me in Firefox, but IE is fine).
However, I found this article describing the data even more interesting, from the Climate Audit Blog. From a data mining / statistics perspective, it was the distribution of the errors that was interesting. I had read in the media (sorry-don't remember where) that there was an average error of 0.15 deg. C due to the Y2K error in the data--that didn't seem too bad. But, at the blog, he describes that the errors are (1) bimodal, (2) postively skewed (hence the positive average error), and (3) typically much larger than 0.15 deg. So while on average it doesn't seem bad, the surface temperature errors are indeed significant.
Once again, averages can mask data issues. Better to augment averages with other metrics, or better yet, visualize!
However, I found this article describing the data even more interesting, from the Climate Audit Blog. From a data mining / statistics perspective, it was the distribution of the errors that was interesting. I had read in the media (sorry-don't remember where) that there was an average error of 0.15 deg. C due to the Y2K error in the data--that didn't seem too bad. But, at the blog, he describes that the errors are (1) bimodal, (2) postively skewed (hence the positive average error), and (3) typically much larger than 0.15 deg. So while on average it doesn't seem bad, the surface temperature errors are indeed significant.
Once again, averages can mask data issues. Better to augment averages with other metrics, or better yet, visualize!
Saturday, August 11, 2007
Rexer Analytics Data Miner Survey, Aug-2007
Rexer Analytics recently distributed a report summarizing the findings of their survey of data miners (observation count=214, after removal of tool vendor employees).
Not surprisingly, the top two types of analysis were: 1. predictive modeling (89%) and 2. segmentation/clustering (77%). Other methods trail off sharply from there.
The top three types of algorithms used were: 1. decision trees (79%), 2. regression (77%) and 3. cluster analysis (72%). It would be interesting to know more about the specifics (which tree-induction algorithms, for instance), but I'd be especially interested in what forms of "regression" are being used since that term covers a lot of ground.
Responses regarding tool usage were divided into never, occasionally and frequently. The authors of the report sorted tools in decreasing order of popularity (occasionally plus frequently used). Interestingly, your own code took second place with 45%, which makes me wonder what languages are being used. (If you must know, SPSS came in first, with 48%.)
When asked about challenges faced by data miners, the top three answers were: 1. dirty data (76%), 2. unavailability of/difficult access to data (51%) and 3. explaining data mining to others (51%). So much for quitting my job in search of something better!
Not surprisingly, the top two types of analysis were: 1. predictive modeling (89%) and 2. segmentation/clustering (77%). Other methods trail off sharply from there.
The top three types of algorithms used were: 1. decision trees (79%), 2. regression (77%) and 3. cluster analysis (72%). It would be interesting to know more about the specifics (which tree-induction algorithms, for instance), but I'd be especially interested in what forms of "regression" are being used since that term covers a lot of ground.
Responses regarding tool usage were divided into never, occasionally and frequently. The authors of the report sorted tools in decreasing order of popularity (occasionally plus frequently used). Interestingly, your own code took second place with 45%, which makes me wonder what languages are being used. (If you must know, SPSS came in first, with 48%.)
When asked about challenges faced by data miners, the top three answers were: 1. dirty data (76%), 2. unavailability of/difficult access to data (51%) and 3. explaining data mining to others (51%). So much for quitting my job in search of something better!
Subscribe to:
Posts (Atom)







{kind=link}